



Photo by Mathew Schwartz on Unsplash
Breaking Search Performance Limits with Domain-Specific Computing
Programming a dedicated chip for search to achieve latencies that are 100x faster


Intro
The demand for advanced search capabilities today is growing exponentially: whether it’s Netflix providing movie recommendations for hundreds of millions of users or Amazon helping customers find the perfect product to buy.
Yet, it is becoming extremely difficult to achieve search at scale due to cloud computing costs, software limits, and queries that are becoming more complex. This makes it nearly impossible to reach consistent real-time latencies of under 100ms.
To solve this, a new direction is to leverage domain-specific computing, while programming a dedicated chip for search, in order to achieve latencies that are 100x faster than what the industry has known. At billion-scale, and at a fraction of the existing cost.
Why is Real-Time Search Important?
Improved User Experience
Faster search results provide a better user experience, as users are able to find the information they are looking for more quickly and efficiently. This can lead to increased engagement and satisfaction with the website or platform.
In 2009, Google’s experiments demonstrated that increasing web search latency from 100 to 400 ms reduces the daily number of searches per user by 0.2% to 0.6%.
In 2019, Booking.com found that an increase of 30% in latency cost about 0.5% in conversion rates — “a relevant cost for our business.”
Data Freshness
For some search queries, the data freshness of the information is crucial. For example, in the case of e-commerce websites, real-time search results can provide the most up-to-date information on product availability, pricing, and shipping information.
Data freshness is also critical for fraud detection because fraudulent activities can occur in real-time or close to it. If data used for fraud detection is outdated, there is a high probability that fraudulent activities could go unnoticed, leading to financial loss and damage to a company's reputation.
Data freshness allows fraud detection systems to analyze the most up-to-date information about transactions and identify suspicious patterns or behaviors that could indicate fraudulent activity. Real-time monitoring of transactions can also help detect and prevent fraudulent activity before it causes significant harm.
Improved Accuracy
Real-time search results improve the accuracy of the information, as the search results are based on the most recent data available in the database. With real-time recommendations, you can provide personalized recommendations for users immediately after they search for products on e-commerce websites.
It’s a challenging task since the user has not yet decided which product they want to buy, so it requires a deep understanding of their preferences and behaviors based on limited data.
In the picture below, on the left are some of Amazon’s results for searching for ‘air Jordans men size 46 with a color twist’. Working with an accurate Real-Time Search Database can help you achieve accurate results as seen on the right, which is exactly what the user is looking for.
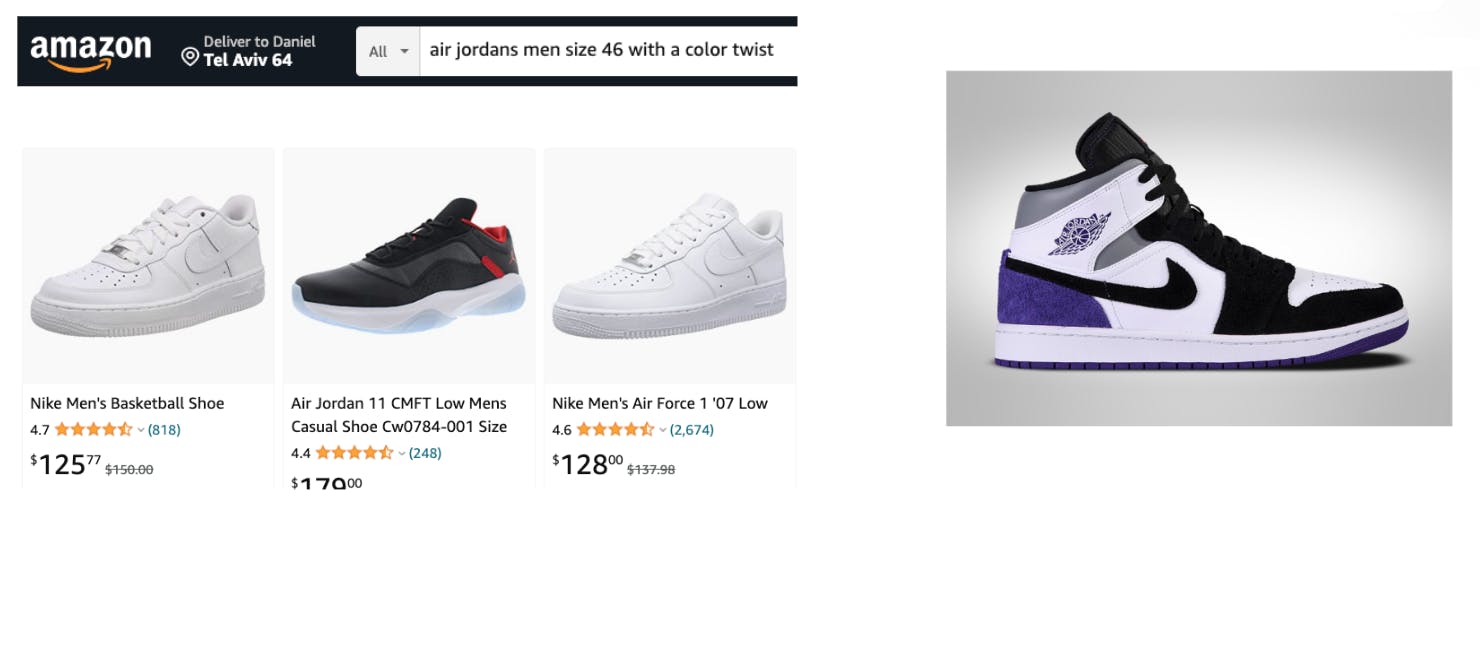
Latency limits today force companies to use superficial business logic that provides sub-optimal results while a faster engine can allow running a deeper and more versatile search that provides the optimal results for the user query.
Real-Time Search Use Cases
Recommendation Systems
Recommendation systems are used to predict customer preferences and provide them with products or services that they might like. Companies can provide a better user experience by accurately recommending products or content and increase revenues by providing personalized recommendations for their customers.
Recommendation systems are used in a variety of industries including retail, entertainment, travel, and the public sector. Netflix recommends movies based on what you’ve watched previously. Amazon uses recommendations to help shoppers find new products they might be interested in purchasing. Finally, Facebook uses its own algorithm to show you relevant ads based on your interests and likes.
Cyber-Security Threat Detection
Real-time threat detection increases architecture security by identifying any malicious activity that compromises the IT infrastructure, website security, and data confidentiality.
Mitigating threats requires quick detection to identify and properly neutralize them before cyber-criminals exploit system vulnerabilities. Website violations can undermine brand reliability, compromise third parties’ personal data, stop the entire operating system, and even generate legal issues for the company.
In order to identify threats, you often want to look for patterns in incoming requests. Some interesting metadata that cyber companies look at includes the IP address, request body, URL, etc.
After observing the requests, you usually compare the pattern to patterns you have stored in your database, and this is where complex search queries at scale become important.
Fraud Prevention
Fraud prevention and cybercrime are connected and always changing. As fraud prevention professionals develop new authentication and fraud detection solutions, fraudsters are networking with each other, monetizing, and exchanging information on the Dark Web. Fraudsters today use sophisticated strategies and malware to succeed in their fraudulent activities.
With exponential growth in online transactions, detecting and mitigating fraud is more complex than ever. You need to be able to handle AI and machine learning workloads, run real-time statistical analysis, and provide consistently high write throughput at low latency. Many Fraud detection search algorithms are limited to 100ms latency at extremely high throughput, and this is why getting real-time results is extremely important.
The Challenges of Achieving Real-Time at Scale
Maintaining latency below 100ms at scale depends on several factors, such as the complexity of the queries, the hardware and network infrastructure, and the indexing strategy used. However, as a rough guideline, maintaining latency below 100ms is extremely challenging at a large scale for a number of reasons:
Millions to Billions of Documents are Becoming Standard
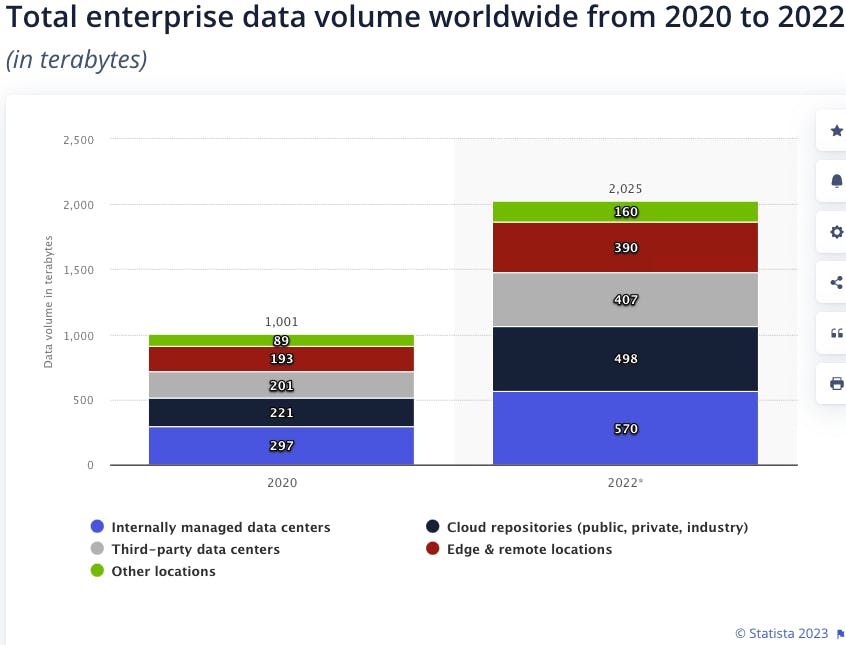
Organization data is growing exponentially, and as the number of documents in the Elasticsearch index grows, the search queries become more complex and resource-intensive, leading to longer query times and higher latency. Elasticsearch can handle large volumes of data, but optimizing the indexing strategy and hardware infrastructure becomes increasingly important as the data grows.
Below you can see a 42.2 percent average annual growth over two years:
Queries Are Becoming More Complex
Let's look at a simple example of an Elasticsearch query that could be difficult to scale. Suppose we have an Elasticsearch index with the following documents representing online orders:
{
"order_id": 1,
"customer_id": 123,
"order_date": "2022-01-01T12:00:00Z",
"total_price": 50.00,
"items": [
{
"item_id": 1,
"item_name": "Product A",
"price": 20.00,
"quantity": 2
},
{
"item_id": 2,
"item_name": "Product B",
"price": 10.00,
"quantity": 3
},
{
"item_id": 3,
"item_name": "Product C",
"price": 5.00,
"quantity": 4
}
]
},
{
"order_id": 2,
"customer_id": 456,
"order_date": "2022-01-02T10:00:00Z",
"total_price": 100.00,
"items": [
{
"item_id": 4,
"item_name": "Product D",
"price": 25.00,
"quantity": 2
},
{
"item_id": 5,
"item_name": "Product E",
"price": 15.00,
"quantity": 3
},
{
"item_id": 6,
"item_name": "Product F",
"price": 10.00,
"quantity": 5
}
]
}
In this e-commerce example, we want to discover the most popular products by the number of orders on our website. So in this query, we’re aggregating the quantity by product and taking the top 10 results. We can construct a query for this using Elasticsearch's query DSL as follows:
GET /orders/_search
{
"size": 0,
"aggs": {
"items": {
"nested": {
"path": "items"
},
"aggs": {
"product": {
"terms": {
"field": "items.item_name.keyword",
"size": 10,
"order": {
"total_quantity": "desc"
}
},
"aggs": {
"total_quantity": {
"sum": {
"field": "items.quantity"
}
}
}
}
}
}
}
}
Aggregating on nested objects can be difficult to scale in Elasticsearch because it requires more resources and time than aggregating on simple fields. This is because nested objects are indexed as separate documents and need to be flattened at query time, which can be resource-intensive and time-consuming.
In the provided example, the query is aggregating on the "items" nested object, which means that for each order document, Elasticsearch needs to:
Load the order document into memory.
Unpack the "items" nested object and create a separate document for each item.
Aggregate the "quantity" field for each item.
Combine the results for all items in the order.
This process can be very resource-intensive, especially if there are many nested objects and many documents to be processed. Additionally, increasing the number of buckets in the aggregation, as in the first example query, can further increase the resource requirements.
To address this issue, it may be necessary to continuously restructure the data or use a different indexing strategy to avoid nested queries and optimize query performance. Even with constant optimization, it’d still be extremely challenging to maintain speed at scale.
Remember that the example above is still a relatively simple scenario, there are plenty of cases where companies run queries that are 10x the complexity of the above query - for example, queries containing 50 aggregations and filters.
High Query Frequency
If the Elasticsearch index receives a high volume of search queries, the system may struggle to maintain low latency if the infrastructure and indexing strategy are not optimized for the query load. In this case, caching strategies and load-balancing techniques can help distribute the query load and reduce latency.
For example, Black Friday is one of the busiest shopping days of the year, and e-commerce sites deal with peak traffic and demand for their products and services due to high concurrency and throughput.
Real-Time Updates
If the Elasticsearch index requires real-time updates, such as in a high-traffic e-commerce website, the system may struggle to maintain low latency as the number of updates and queries increases. In this case, optimizing the indexing and sharding strategies, as well as implementing efficient update strategies, can help reduce latency.
Overall, maintaining low latency below 100ms at a large scale requires careful planning and optimization of the Elasticsearch infrastructure, including the hardware, network, indexing strategy, caching, and load balancing techniques.
Programming a Dedicated Search Processing Unit (SPU)
There is a hard limit on the performance you can achieve with even the most powerful CPUs today.
CPUs are designed to handle a wide range of tasks, but they are not optimized for any specific task. As a result, they are limited in processing power and parallelism, especially when dealing with complex algorithms, large datasets, or where the software is not well parallelized.
GPUs are designed to handle specific types of tasks related to graphics processing, such as rendering and image processing. While they can also perform general-purpose computing tasks, they are not optimal for handling large amounts of data and complex search queries.
FPGAs (Field Programmable Gate Arrays), domain-specific virtual chips that can be programmed in the cloud via services like AWS’s F1 are extremely efficient at achieving speed at scale in several ways in order to accelerate Search-Engine Databases:

Firstly, FPGAs are highly parallelizable and can perform thousands of computations in parallel, making them well-suited for high-throughput applications such as data processing and search indexing. In an Elasticsearch cluster, FPGAs can be used to accelerate data processing and indexing by offloading compute-intensive tasks such as data compression, hashing, and filtering.
Secondly, FPGAs can be used to accelerate search queries by offloading some of the processing from the CPU to the FPGA. For example, FPGAs can be programmed to perform specific query operations such as term matching, sorting, and filtering, thereby reducing the workload on the CPU and improving query performance.
Thirdly, FPGAs can be used to optimize the network infrastructure in an Elasticsearch cluster. For example, FPGAs can be used to implement high-speed networking protocols such as RDMA (Remote Direct Memory Access), which can reduce network latency and improve data transfer rates.
Optimized Search Architecture
FPGAs specifically designed for search, or 'Search Processing Units' (SPU) greatly enhance the speed of the inverted index and data pipeline in Elasticsearch by leveraging their parallel processing capabilities and customizable hardware design. Here’s how:
Inverted Index
An inverted index is a data structure used by Search Engines to quickly locate documents that contain a specific term. SPUs programmed for search can accelerate the creation and processing of inverted indices by parallelizing the term indexing process across multiple computing units. By offloading the creation of inverted indices to SPUs, the CPU can be freed up to handle other processing tasks, resulting in faster query times.
Data Pipeline
Search Engines process large amounts of data through a pipeline that includes data transformation, filtering, and indexing. SPUs can accelerate the data pipeline by offloading compute-intensive tasks such as data compression, filtering, and hashing to the SPU. This allows for faster data processing and indexing, resulting in improved query performance.
Integrating the Chip into a Cloud Database
By programming the SPU in the cloud, we can provide an Elasticsearch-compatible API and improve scalability, reduce infrastructure costs, and provide high-performance search capabilities.
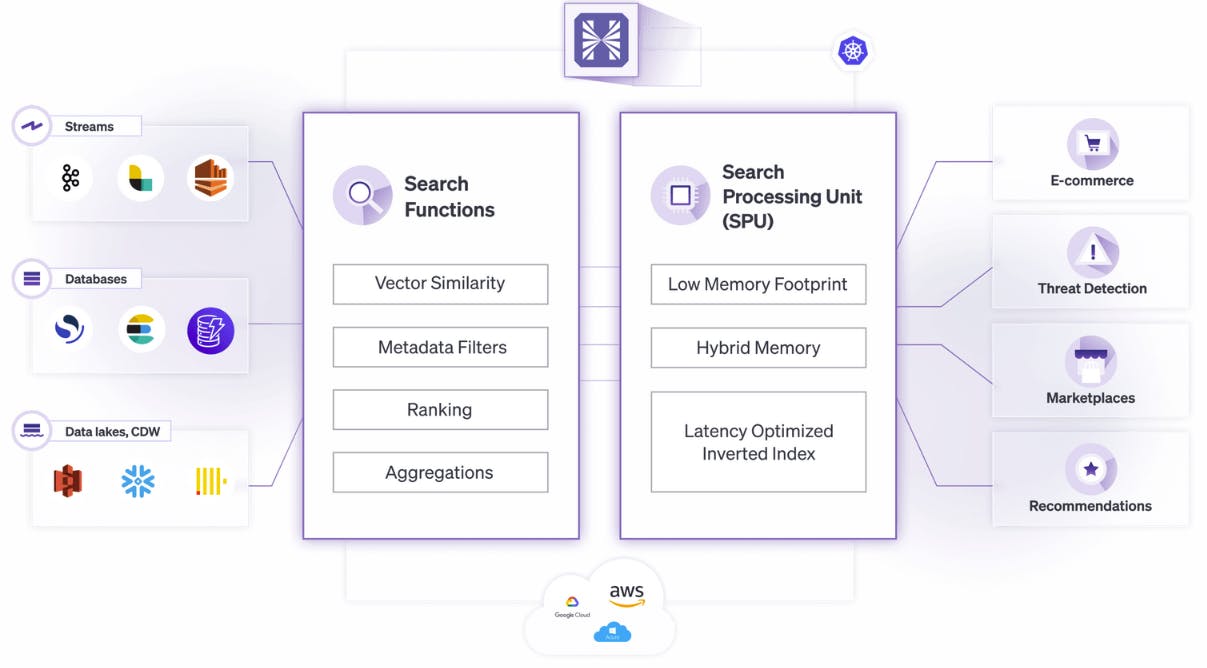
By developing an SPU solution in the cloud, the Elasticsearch API can be scaled up or down depending on demand. This allows for efficient resource utilization, ensuring that the API can handle large volumes of traffic and provide fast search results.
The SPU cloud solution reduces infrastructure costs by leveraging the pay-as-you-go pricing model offered by cloud providers. Instead of investing in expensive hardware and maintenance costs, Hyperspace is hosted in the cloud and scaled up or down as needed, providing cost savings and flexibility.
The most impactful advantage is that you get high-performance search capabilities by accelerating query processing and indexing. By offloading compute-intensive tasks to the SPU, Hyperspace’s Elastic API provides 10x faster query times and improved search performance, leading to better user experiences and increased customer satisfaction.
Breaking the Limits of Search
Using the SPU cloud-based database, we can break the limits of search in recommendation systems, fraud detection, and cyber threat detection by providing high-performance search capabilities and real-time data processing. By accelerating search algorithms and handling large volumes of data in real-time, we’ve improved the accuracy, speed, and efficiency of search-based applications.
In the graph below you can see that the Hyperspace Search Database reaches latencies under 10ms on P95, providing consistent results on datasets with over 100m documents.
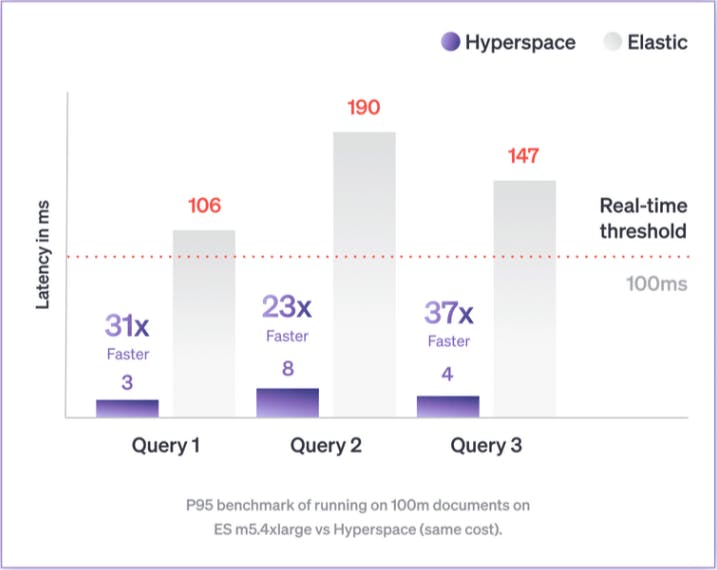
Run Complex Queries
Better search latencies mean the Search Database can process and return results for complex queries far more quickly, allowing you to run extremely complex combinations of both keyword search and vector search queries.
Higher Throughput
You also gain increased query throughput: with lower search latencies, the Search Engine Database can handle a much larger volume of queries per second. This means that you can run more queries without overloading the search engine and causing slow response times.
Cost Reduction
Lower latencies reduce server costs by reducing server load, improving resource utilization, reducing maintenance resources, and improving scalability. By optimizing server usage and reducing operating costs, lower latencies save time and resources.